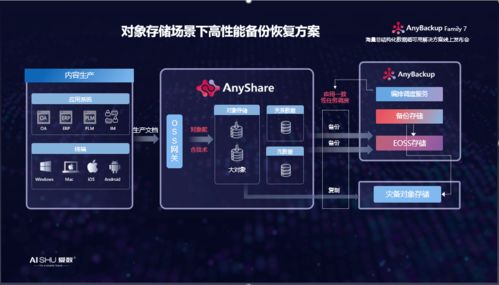
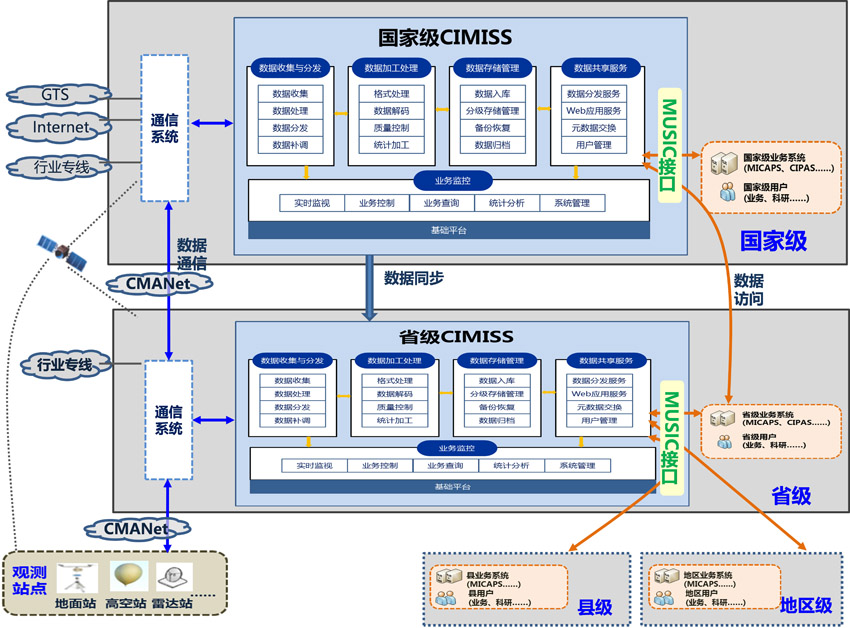
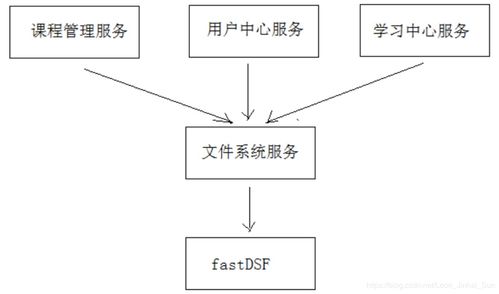
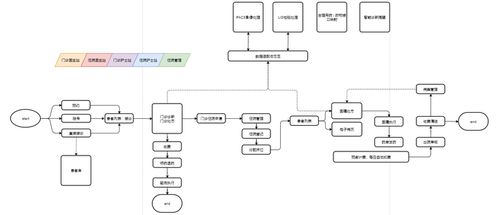
基于大数据的舆情分析系统架构 数据处理与存储支持服务详解
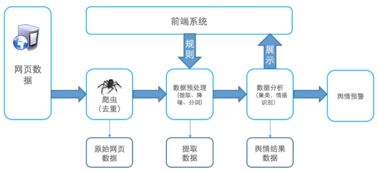
随着社交媒体和数字信息的爆炸式增长,对网络舆情的实时、精准分析变得至关重要。一套高效的基于大数据的舆情分析系统,其核心能力很大程度上依赖于健壮的数据处理与存储支持服务。本文将深入探讨该架构中数据处理与存储层的设计理念、关键组件与技术选型。
一、 总体架构定位
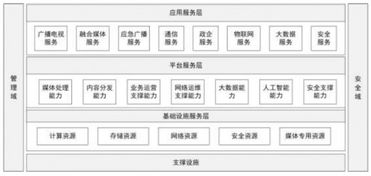
在舆情分析系统的分层架构中,数据处理与存储支持服务位于数据层,是连接底层数据采集与上层分析应用的桥梁。其主要职责是承接海量、多源、异构的原始舆情数据(如新闻、微博、论坛帖子、评论、视频弹幕等),经过一系列处理,转化为清洁、规整、易于分析的高价值数据资产,并提供高效、可靠的存储与访问服务。
二、 数据处理流程与关键技术
数据处理流程通常遵循“采集-清洗-集成-转换-加载”的管道模式,并引入实时流处理以满足时效性要求。
- 多源数据采集与接入:
- 技术组件:使用如Flume、Logstash、Sqoop等工具,以及自研的API爬虫框架,从网站、API接口、移动应用、数据库等多种信源实时或批量采集数据。
- 挑战与策略:应对反爬机制、处理不同数据格式(JSON、XML、HTML、纯文本)、保证数据的完整性与连续性。
- 实时流处理:
- 技术选型:Apache Kafka作为高吞吐量的分布式消息队列,是流数据的“中枢神经”。后续使用Apache Flink或Apache Storm进行实时计算,实现数据的即时清洗、初步筛选(如关键词过滤)、情感倾向性基础判断。
- 价值:对突发事件、热点话题实现分钟级甚至秒级的感知与响应。
- 批处理与数据清洗:
- 技术选型:Apache Spark或Hadoop MapReduce用于处理海量历史数据及复杂的清洗转换任务。
- 核心任务:
- 去重与去噪:消除重复转载、垃圾广告、无关信息。
- 结构化提取:从非结构化文本中抽取实体(人名、机构名、地名、产品名)、关键词、主题。
- 标准化:统一编码、时间格式、单位等。
- 情感标注:结合词典与机器学习模型,为文本打上情感标签。
- 数据集成与转换:
- 将清洗后的数据与内部业务数据(如客户信息、产品目录)进行关联。
- 将数据转换为适合后续分析与挖掘的模型,例如构建“事件-观点-情感”关系图谱的底层数据表。
三、 数据存储架构设计
舆情数据的多模态(文本、图片、视频链接、结构化元数据)和访问模式多样性(实时查询、批量分析、模型训练)要求采用混合存储策略。
- 分布式文件系统:
- 角色:存储最原始的、未经处理的或经过简单分区的海量数据,作为数据湖的基底。
- 技术选型:Hadoop HDFS或云对象存储(如AWS S3,阿里云OSS)。特点是成本低、容量无限扩展、适合顺序访问。
- NoSQL数据库:
- 角色:存储清洗后、需要支持高并发实时查询和灵活模式的数据。
- 技术选型:
- 宽列存储:如Apache HBase、Cassandra。适用于存储舆情事件详情、用户画像信息,支持按行键快速查询。
- 文档数据库:如MongoDB、Elasticsearch。Elasticsearch凭借其强大的全文检索和近实时搜索能力,常作为处理后的舆情文本的核心存储与索引引擎,支持复杂聚合分析。
- 关系型数据库与数据仓库:
- 角色:存储高度结构化、用于BI报表、趋势分析和模型训练的特征数据、结果数据。
- 技术选型:MySQL/PostgreSQL用于存储元数据和管理信息;云数据仓库(如Snowflake、阿里云MaxCompute)或基于Hive的离线数仓用于承载大规模分析任务。
- 缓存层:
- 角色:加速热点数据(如正在爆发的热点事件详情、实时统计仪表盘数据)的访问。
- 技术选型:Redis或Memcached。
四、 支持服务与数据治理
- 元数据管理:记录数据的来源、格式、含义、处理历史、血缘关系,确保数据的可追溯性与可信度。
- 数据质量监控:设立数据质量检查点,监控数据采集的完整性、清洗的有效性、存储的可用性。
- 资源调度与协调:使用YARN或Kubernetes管理计算资源,使用ZooKeeper协调分布式组件状态。
- 安全与权限:实施数据加密(传输中/静止时)、访问控制、脱敏处理,确保合规性。
五、
一个成功的舆情分析系统,其数据处理与存储支持服务必须兼具高吞吐、低延迟、高可靠、易扩展的特性。通过融合流批一体的处理框架(如Flink)、分层分域的混合存储方案,并辅以完善的数据治理工具,才能将汹涌而来的数据洪流,转化为驱动舆情洞察、辅助决策制定的清澈“信息活水”。这套架构不仅支撑了实时预警、情感分析、趋势预测等核心应用,也为更高级别的NLP模型训练和人工智能应用奠定了坚实的数据基石。
如若转载,请注明出处:http://www.ftqimeisi.com/product/63.html
更新时间:2026-06-19 22:19:23