爬虫数据存储 MySQL在数据处理与存储支持服务中的核心地位
随着互联网信息的爆炸式增长,爬虫技术已成为数据获取的重要手段。爬取到的原始数据往往是海量、杂乱且非结构化的,如何高效、可靠地处理和存储这些数据,是决定整个数据价值链路成败的关键环节。在众多存储方案中,关系型数据库的代表——MySQL,凭借其成熟、稳定、灵活的特性,在爬虫数据的处理与存储支持服务中扮演着核心角色。
一、 爬虫数据存储的挑战与需求
爬虫数据通常具有以下特点:
- 数据量大:需要存储数百万甚至数亿条记录。
- 结构多变:不同网站的结构各异,数据字段可能频繁增减或变更。
- 关联复杂:数据间可能存在复杂的层级、关联关系(如文章与评论)。
- 需要快速读写与查询:数据分析、去重、监控等场景要求低延迟的存取能力。
- 要求高可靠性与持久化:数据是宝贵资产,不能轻易丢失。
这些挑战要求存储系统不仅要能“存得下”,更要“存得好”、“取得快”。
二、 MySQL作为存储核心的优势
MySQL能够成为主流选择,源于其多方面的优势,完美契合了爬虫数据处理与存储的需求:
- 成熟稳定,生态完善:作为最流行的开源关系型数据库之一,MySQL拥有极佳的稳定性、丰富的文档和强大的社区支持。其周边工具链(如管理工具、监控工具、备份工具)非常成熟,极大地降低了运维成本。
- 清晰的结构化存储:MySQL要求预先定义表结构(Schema),这强制数据工程师对爬取的数据进行梳理和建模。这种结构化方式虽然初期需要设计,但长远来看,它保证了数据的一致性、完整性和规范性,为后续的数据分析、关联查询奠定了坚实基础。例如,可以轻松建立“商品表”、“价格历史表”、“店铺表”之间的外键关联。
- 强大的SQL查询与分析能力:SQL语言是数据处理领域的通用语。利用SQL,可以极其灵活地对爬虫数据进行过滤、聚合、连接、统计等复杂操作。无论是简单的去重(
SELECT DISTINCT),还是复杂的多表关联分析,MySQL都能高效完成,这是许多NoSQL数据库难以比拟的。
- 事务支持与数据完整性:ACID(原子性、一致性、隔离性、持久性)事务特性确保了在并发写入(如多个爬虫节点同时入库)或复杂的数据更新操作时,数据不会错乱或丢失。这对于需要保证数据准确性的业务场景至关重要。
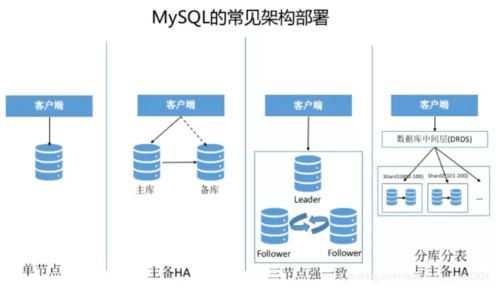
- 优异的性能与可扩展性:通过合理的索引设计(如对URL字段建立唯一索引以实现高效去重)、查询优化、以及读写分离、分库分表等架构方案,MySQL能够支撑海量数据的读写请求。InnoDB存储引擎在并发处理和崩溃恢复方面表现卓越。
- 灵活的数据处理支持:MySQL可以作为数据处理管道中的重要一环。爬虫程序可以将清洗和去重后的数据直接写入MySQL。MySQL又可以作为数据源,供BI工具、报表系统或应用程序直接读取和分析,形成了“爬取 → 清洗 → 入库(MySQL)→ 服务应用”的流畅数据流。
三、 数据处理与存储支持服务实践
在实际的爬虫项目中,围绕MySQL构建的数据处理与存储服务通常包含以下层次:
- 数据清洗与标准化层:在数据入库前,通过独立的脚本或ETL工具,对原始数据进行清洗(去除HTML标签、纠正乱码)、格式化(统一日期、数字格式)和标准化(统一计量单位、枚举值映射)。
- MySQL存储层:
- 数据库与表设计:根据业务逻辑进行详细的数据库设计,合理规划表结构、字段类型、索引和分区策略。
- 写入优化:采用批量插入(
INSERT ... VALUES (),(),...)、连接池、异步写入等方式,应对高并发写入压力。
- 存储过程与触发器:对于某些固定的数据转换或更新逻辑,可以使用存储过程或触发器在数据库层面实现,提高效率。
- 数据服务层:以MySQL为核心,向上提供数据访问接口。这可以是直接的数据库连接供内部系统使用,也可以是通过构建RESTful API或GraphQL服务,将数据安全、可控地暴露给前端或其他业务系统。
- 备份、监控与容灾层:建立定期的数据库备份机制(如mysqldump、XtraBackup),并实施主从复制(Replication)以实现读写分离和数据冗余。监控数据库的性能指标(QPS、慢查询、连接数等),确保服务稳定。
四、 与其他存储方案的协同
虽然MySQL是核心,但在现代爬虫架构中,它常常与其他存储系统协同工作,形成混合持久化策略:
- 原始存储:将未经处理的原始HTML或JSON响应暂存于对象存储(如S3、OSS)或分布式文件系统(如HDFS),作为原始档案。
- 高速缓存与去重:使用Redis或布隆过滤器(Bloom Filter)进行URL去重和热点数据缓存,减轻MySQL的压力。
- 大数据分析:对于需要深度挖掘的海量历史数据,可以定期将MySQL中的数据同步到数据仓库(如ClickHouse)或大数据平台(如Hive)中进行离线分析。
###
MySQL在爬虫数据存储领域绝非过时的技术,而是经过时间检验的可靠基石。它通过提供结构化、一致化、可高效查询的数据存储能力,将杂乱的爬虫数据转化为真正可用的数据资产。构建以MySQL为核心,多种存储技术互补的数据处理与存储支持服务,是应对复杂爬虫数据管理挑战、最大化数据价值的高效路径。成功的爬虫项目,必然建立在坚实、灵活的数据存储架构之上。
如若转载,请注明出处:http://www.ftqimeisi.com/product/51.html
更新时间:2026-05-30 21:08:46